
This article dives into the importance of resource naming conventions within Microsoft Fabric and introduces you to our Microsoft Fabric Naming Conventions framework. Additionally, we’ll explore the benefits of a well-defined naming framework and common pitfalls to avoid.
Our experience spans multiple projects leveraging various components of Microsoft Fabric, a unified, end-to-end analytics and data platform—these include Data Factory, Data Engineering, Data Science, Data Warehouse, Real Time Analytics, Power BI, Data Activator, and OneLake. Based on this experience, we feel that establishing clear naming conventions is crucial, especially if you have a large enough Fabric implementation with a number of different Fabric artifacts like lakehouses, notebooks, data pipelines, semantic models, reports, experiments, machine learning models, and so on.
Knowing that you need naming conventions is not enough; you need some guidelines, and at the time of writing this blog, Microsoft has not released any Fabric naming conventions. We at XTIVIA have attempted to fill this void by sharing our own Microsoft Fabric naming conventions. This guide will equip you with a practical 6-parameter framework for naming Microsoft Fabric resources. Implementing this framework from the outset significantly improves application maintainability and reduces long-term costs.
Why Do You Need Standardization of Naming in Microsoft Fabric?
If you come from a reporting background using Power BI, you are probably used to naming conventions in your data models (table and column names), but it is unlikely that you paid much attention to naming your reports and datasets (now called Semantic Models).
If, on the other end, you come from a data engineering background, you are likely used to robust software engineering practices that include naming and coding conventions for pretty much everything.
In Microsoft Fabric, you end up bringing together your data engineers, your report builders, your data analysts, your data scientists, and pretty much everybody dealing with data in your enterprise, and you will have all these team members with disparate backgrounds creating a plethora of Fabric artifacts. If you don’t provide clear naming guidelines, you will quickly find yourself with a messy sprawl that makes the software purists in your team cringe and hard on your team members to find the artifacts that they care about. While Microsoft Fabric does have a way to filter Fabric artifacts by type (data pipeline versus notebook, etc.) and workload (data factory vs data engineering, etc.), if you have even tens of Fabric artifacts with arbitrary names, it can quickly get overwhelming at first glance.
Now that you have an idea of why naming conventions are crucial in Fabric let’s move on to a practical 6-parameter framework for naming resources that every Fabric data architect and data engineer should be aware of to improve the implementation experience. With this guide, you will learn not just how to name Fabric resources but how to do it effectively.
Stay with us as we delve deeper and provide a comprehensive and actionable framework.
Mastering Microsoft Fabric Resource Naming
Ready to build crystal-clear resource names? Let’s explore the 6-parameter framework!
6-Parameter Microsoft Fabric Resource Naming Framework
This framework of optional and mandatory parameters empowers you to craft clear and consistent names for your Fabric resources, leveraging six parameters that balance both detail and readability.
- Project name – Usually mandatory
- Fabric Experience group – Optional
- Component type – Mandatory
- Medallion index – Optional
- Medallion layer – Optional
- Purpose – Usually mandatory
Why this balance?
While using all parameters can offer maximum detail, overly long names can hinder readability. This framework allows you to customize the level of detail based on your needs. We’ll provide specific recommendations for using mandatory, usually mandatory, and optional parameters with various components. The parameters, project name, and purpose are listed as usually mandatory — more on this later, but this means you can use both or definitely one. Ultimately, the decision on how much detail to include depends on the number and complexity of Microsoft Fabric artifacts in your environment as well as your organization’s maturity and preferences.
Microsoft Fabric offers a Deployment Pipelines feature that allows the deployment of artifacts from one environment (or pipeline stage) to another (for example, from a non-production to a production environment) for most Fabric components. We strongly recommend using Deployment Pipelines with Fabric, and since Deployment Pipelines expect to perform auto-pairing of resources in different environments by name, we avoided using environment as one of the resource naming parameters. While we think there is value in having an environment as part of a resource name, we think there is more value in using Deployment Pipelines and having different resource names between environments. While doable would be tedious to set up (since you would have to remember to change names in each higher environment after auto-pairing had taken place).
By following these guidelines, you’ll create self-documenting resource names that promote better organization, understandability, and maintainability within your Microsoft Fabric environment.
Universal Naming Conventions:
Before diving deeper, here are some universal naming conventions to keep in mind:
- Decide on whether you want to allow abbreviations or acronyms in resource names, and if so, any restrictions on them.
- If you abbreviate terms or use acronyms, be consistent in doing so for all artifacts using the same terms.
- Always use lowercase letters for resource names.
- Separate parameters and elements within parameter names with underscores (“_”) or hyphens (“-“) instead of spaces (” “).
Microsoft Azure recommends using lowercase with hyphens for naming resources and not camelcase. To keep consistency with Microsoft naming conventions, we have decided to go with lower case. Additionally, the usage of lowercase improves readability; camel cases sometimes be visually overwhelming, especially for longer names. And the choice between underscores (“_”) or hyphens (“-“), we will leave it up to you to decide based on the conventions you are following in your cloud projects. In this blog, while providing examples, we have used lowercase and underscores (“_”).
We’ll now delve into each parameter in detail in the following sections.
Microsoft Fabric Naming Convention Component #1: Project Name (Usually mandatory)
The first parameter, project name, is usually mandatory, particularly if you have multiple projects in a single Fabric account. Additionally, even if you only have a single Fabric project within your Fabric tenant, we strongly recommend including the project name parameter in your resource names. And lastly, a project name is especially helpful for naming workspaces, since they are the foundation of Microsoft Fabric and most other resources are built within them.
Project names can be multiple words separated by underscores (“_”).
Here are some examples of how to name a Fabric workspace:
customer360_workspace(where customer360 is the project name)edw_workspace(where EDW is the project name and stands for “Enterprise Data Warehouse”)quarterly_financials_workspace(where “Quarterly Financials” is the project name)
We highly recommend using project names for workspaces to improve organization and clarity. Even if you only plan to implement one Microsoft Fabric project at this time, we recommend futureproofing your Fabric set-up by using a meaningful project name in your workspace name, as you may find yourself implementing more Fabric projects as new business needs arise.
Microsoft Fabric Naming Convention Component #2: Fabric Experience Group (Optional)
The second parameter allows you to optionally include the Microsoft Fabric experience group. Microsoft Fabric currently offers eight experiences, and adding this element to the resource name helps with sorting and grouping resources within a workspace by experience.
We recommend using these abbreviations to represent the experience group names:
- Power BI: pbi
- Data Factory: df
- Synapse Data Engineering: de
- Synapse Data Science: ds
- Synapse Data Warehouse: dw
- Synapse Real-Time Analytics: rta
- Data Activator: da
By using these consistent abbreviations, you can easily identify which resources belong to a specific Microsoft Fabric experience.
Microsoft Fabric Naming Convention Component #3: Component Type (Mandatory)
The third and only truly mandatory parameter is the component type. Every Microsoft Fabric resource falls under a specific component type, which essentially represents the “type” you see for each resource within the Fabric workspace UI. However, our naming framework takes this a step further by incorporating component names directly into resource names for improved structure and clarity.
Here’s a table outlining the different Microsoft Fabric experiences and their corresponding recommended component type abbreviations:
| Microsoft Fabric experience | Component type | Recommended component abbreviation |
| Power BI | Report | report |
| Paginated Report | paginated_report | |
| Scorecard | scorecard | |
| Dashboard | dashboard | |
| Dataflow | dataflow | |
| Datamart | datamart | |
| Streaming Dataset | streaming_dataset | |
| Streaming Dataflow | streaming_dataflow | |
| Data Factory | Data Pipeline | pipeline |
| Dataflow Gen2 | dataflow | |
| Synapse Data Engineering | Lakehouse | lakehouse |
| Notebook | notebook | |
| Spark Job Definition | sparkjob | |
| Environment | environment | |
| Spark Data Warehouse | Warehouse | warehouse |
| Synapse Real-Time Analytics | Eventhouse | eventhouse |
| KQL Queryset | kqlqueryset | |
| Eventstream | eventstream | |
| Reflex | reflex | |
| Data Science | ML Model | mlmodel |
| Experiment | experiment | |
| Notebook | notebook | |
| Environment | environment |
If you decide to include Microsoft Fabric experience group parameter (#2) as well as the component type abbreviation in your resource names, you instantly convey the resource’s connection to a specific Fabric experience; additionally, group the components of the same Microsoft Fabric experience together. This promotes further improved organization and understanding within your Microsoft Fabric environment.
Note: You have probably noticed that the values in the “Recommended component abbreviation” column in the table above are not much of an abbreviation in most cases and actually are the full component type names. We will defer to you to decide whether you wish to use our longform names or abbreviate them—for example, use nb for notebook, mlm for ML Model, lh for Lakehouse, and so on. Establish a standard and consistently implement the standard!
Microsoft Fabric Naming Convention Component #4: Medallion Index (Optional, Recommended for Lakehouse)
The medallion index is an optional parameter, but we strongly recommend using it when naming lakehouses. It has a one-to-one mapping with the medallion layer, as shown in the table below:
| Medallion index | Medallion layer |
| 100 | bronze |
| 200 | silver |
| 300 | gold |
Including a medallion index helps sequence your lakehouses within a workspace, promoting clear comprehension and analysis of the data flow. For example, names like de_lakehouse_100_bronze_customer360, de_lakehouse_200_silver_customer360 explicitly depict the processing stages.
Microsoft Fabric Naming Convention Component #5: Medallion Layer (Optional, But Highly Recommended)
While the medallion index provides a sequencing element, the medallion layer itself can be used independently as well. Even though it’s technically an optional parameter, using the medallion layer offers significant benefits for data engineers and architects.
Here’s why:
- Clarity and Differentiation: The medallion layer clearly differentiates Microsoft Fabric components based on their function within the data processing pipeline (bronze, silver, gold). This makes it easier to understand the flow of data at a glance.
- Customization: You can tailor the medallion layer terminology to align with your organization’s existing conventions. For example, you might use terms like “bronze, silver, and gold,” or “landing, raw, validated, and enriched,” or something else that resonates with your team.
By incorporating the medallion layer, even if you choose not to use the medallion index for sequencing, you’ll still enhance the clarity and maintainability of your Microsoft Fabric environment.
For example, you might have a silver layer lakehouse and name it customer360_de_lakehouse_200_silver or a notebook that ingests customer data into the bronze layer and call it de_notebook_100_bronze_ingest_customer_data.
Microsoft Fabric Naming Convention Component #6: Purpose (Usually Mandatory)
The sixth parameter, which is usually mandatory, defines the functional purpose of a resource. This helps everyone understand what the resource does within the system.
To give a functional name to a Microsoft Fabric component, a single word might not always suffice. We recommend using two or more words separated by underscores (“_”) to clearly describe the resource’s function.
Here are some “purpose” examples:
customers_abandoned_cartcustomers_successful_upsellload_bronze_customer_data_to_silver
By clearly defining the purpose, you create self-documenting resource names that improve maintainability and understanding for your entire team.
Bringing It All Together With Examples
In this section, we will take a few Microsoft Fabric components and name them using our 6-parameter Microsoft Fabric Resource Naming framework.
Naming Conventions for Microsoft Fabric Workspaces
Microsoft Fabric accounts can hold numerous workspaces, where these workspaces serve as the central hubs for most Fabric components. As recommended earlier, using the usually mandatory project name parameter is highly beneficial for workspace names, especially for organization purposes.
Additionally, if your workspaces are segregated based on the medallion layer (bronze, silver, gold), you can leverage the medallion layer parameter for further clarity. At the time of publication of this article, Microsoft Fabric Data Pipelines are scoped to their workspace and can’t interact with items in other workspaces; keep this constraint in mind if you are considering separating workspaces based on the medallion layer.
The sample parameter names while naming a workspace are:
- Project name: customer360
- Medallion index: 100
- Medallion layer: bronze
- Component name: workspace
Example Workspace Names:
Here are some examples showcasing different ways to name workspaces, with varying uses of optional parameters:
customer360_workspace(using only the project name as the usually mandatory parameter)customer360_workspace_bronze(using both project name and medallion layer)customer360_workspace_100_bronze(using project name, medallion index, and medallion layer)
Key Takeaways:
- Workspaces are fundamental to Microsoft Fabric organization.
- Utilize the project name parameter (usually mandatory) for clear workspace identification.
- The medallion index and medallion layer parameters (optional) are helpful for medallion-based segregation.
- The purpose parameter is usually redundant for workspace names when you include the project name parameter.
Naming Conventions for Microsoft Fabric Data Pipelines
Data Pipelines in Data Factory are the workhorses that move data across your Microsoft Fabric environment. They can be specific to a single medallion layer (bronze, silver, gold) or handle transformations across multiple layers. While crafting Data Pipeline names, keep in mind the optional parameters available:
Example Pipeline Names:
Here are some examples showcasing how to use optional parameters for better Data Pipeline names:
pipeline_load_customer_orders(no optional parameters used, suitable for generic pipelines)pipeline_bronze_load_customer_orders(using the optional parameter, medallion layer, for clarity)df_pipeline_bronze_load_customer_orders(using the optional parameter, Fabric experience group and medallion layer for component grouping and clarity)
Naming Conventions for Microsoft Fabric Notebooks
While not directly part of data pipelines, Notebooks within Synapse Data Engineering play a crucial role in Microsoft Fabric. These interactive coding environments offer a space for data engineers and data scientists to:
- Explore and analyze data
- Ingest data into OneLake
- Extract and load data or move/transform data
- Build machine learning models
Example Notebook Names:
Here are some examples showcasing notebook names:
notebook_load_bronze_customer_data_to_silver(no optional parameters used)notebook_silver_load_bronze_customer_data_to_silver(using the optional parameter, medallion layer, for better context)
By incorporating these recommendations, you’ll create informative notebook names that reflect their purpose and integration within your Microsoft Fabric environment.
Naming Conventions for Microsoft Fabric Lakehouses
Microsoft Fabric lakehouses, residing within the Synapse Data Engineering experience, serve as the cornerstone for your data storage needs. These unified solutions can hold both structured data (tables) and unstructured/semi-structured data (files).
Medallion Layer and Lakehouse Organization:
It’s recommended to have separate lakehouses for each medallion layer (bronze, silver, gold) within your data architecture. This segregation promotes a clear organization of data at different processing stages.
Optional Parameters for Clear Naming:
- Medallion Index (Optional): While not mandatory, including the medallion index (e.g., 100, 200) helps sequence your lakehouses within the workspace (e.g., 100_bronze).
- Medallion Layer (Recommended): This parameter clearly defines the processing stage (bronze, silver, gold) associated with the lakehouse.
Example Lakehouse Names:
Here are some examples showcasing how to use optional parameters, Fabric experience, medallion index, and medallion layer for better lakehouse names across medallion layers.
customer360_de_lakehouse_100_bronzecustomer360_de_lakehouse_200_silvercustomer360_de_lakehouse_300_gold
We have included customer360, the project name as well in these example names.
By adopting these recommendations, you’ll create informative lakehouse names that make it easier to understand how a given lakehouse fits into your overall Microsoft Fabric architecture.
Naming Conventions for Microsoft Fabric Reports
Reports are a core component in the Power BI Fabric experience that delivers a multi-perspective view into a semantic model to your primary audience — business users. With this in mind, we recommend focusing on the mandatory parameters while naming reports to ensure clarity and understandability.
Why Prioritize Mandatory Parameters?
- Business User Focus: Since business users are the primary consumers of reports, the names should be clear and easy to understand. Using detailed, descriptive names helps them quickly identify the report’s purpose and the data it presents.
- Minimal Optional Parameters: While optional parameters can add context, they shouldn’t be the primary focus. Keeping the name concise and user-friendly is key.
Example Report Names:
Here are some examples showcasing effective report names:
report_customer_orders— no optional parameters used though the “usually mandatory” purpose is included resulting in a clear and concise namereport_customer_spend— similar to the example above
Naming Other Microsoft Fabric Components
Building on the principles established for workspaces, pipelines, notebooks, lakehouses, and reports, here’s how you can define clear and informative names for other Microsoft Fabric components:
- Data Flow (Data Factory):
- Mandatory: purpose (e.g., dataflow_customer360_data_transformation)
- Optional: Microsoft Fabric Experience Group (abbreviation: df)
- Data Warehouse (Synapse Data Warehouse):
- Mandatory: purpose (e.g., warehouse_customer_orders)
- Optional: Medallion Layer (relevant for specific architectures)
- Spark Job Definition (Apache Spark):
- Mandatory: purpose (e.g., sparkjob_order_ingestion)
- Optional: Can include relevant processing stage or data source (e.g., sparkjob_bronze_order_ingestion)
- ML Model (Synapse Data Science):
- Mandatory: purpose (e.g., mlmodel_customer_spend_prediction)
- Optional: Medallion Layer (if relevant)
- Scorecard (Power BI):
- Mandatory: purpose (e.g., scorecard_sales_performance)
- Optional: Microsoft Fabric Experience Group (abbreviation: pbi)
- Dashboard (Power BI):
- Mandatory: purpose (e.g., dashboard_regional_order_summary)
- Optional: Microsoft Fabric Experience Group (abbreviation: pbi)
By adopting these naming conventions, you’ll create a well-organized and self-documenting Microsoft Fabric environment that promotes collaboration, maintainability, and ease of use for all team members.
Viewing Microsoft Fabric Components
In this section, we take a look at listings of Microsoft Fabric components named using our naming conventions.
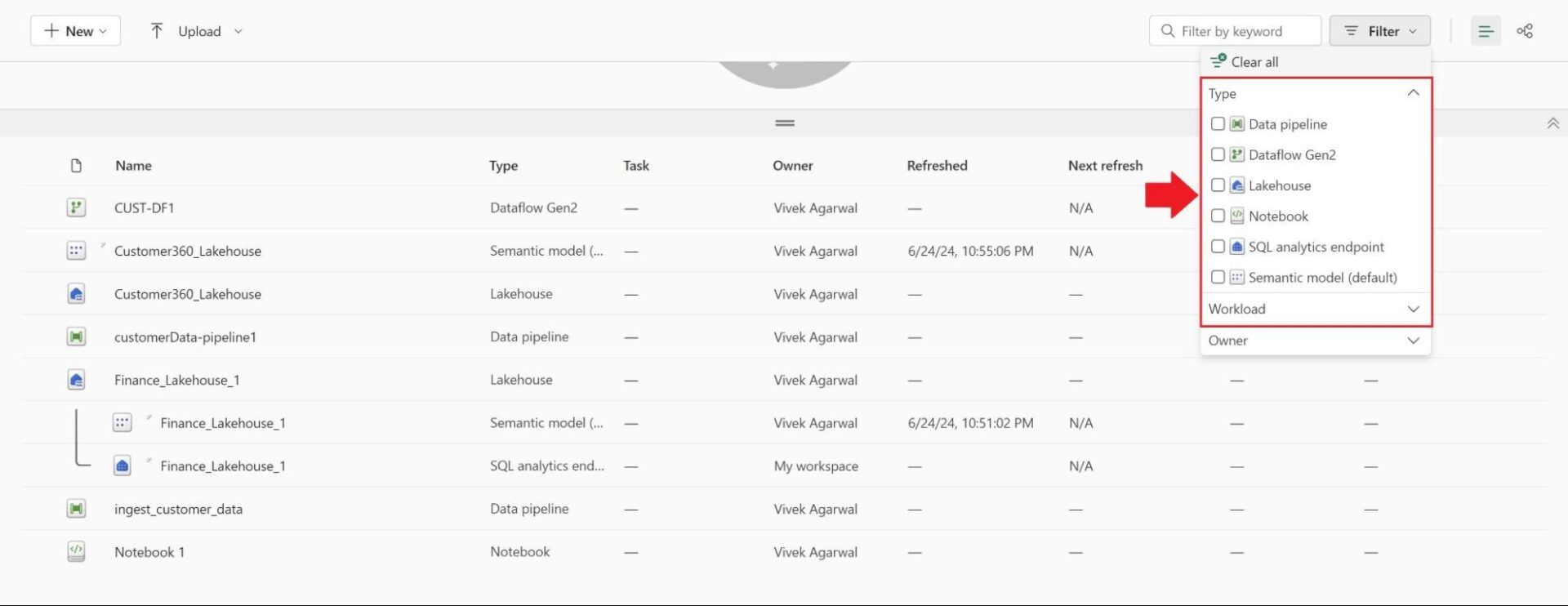
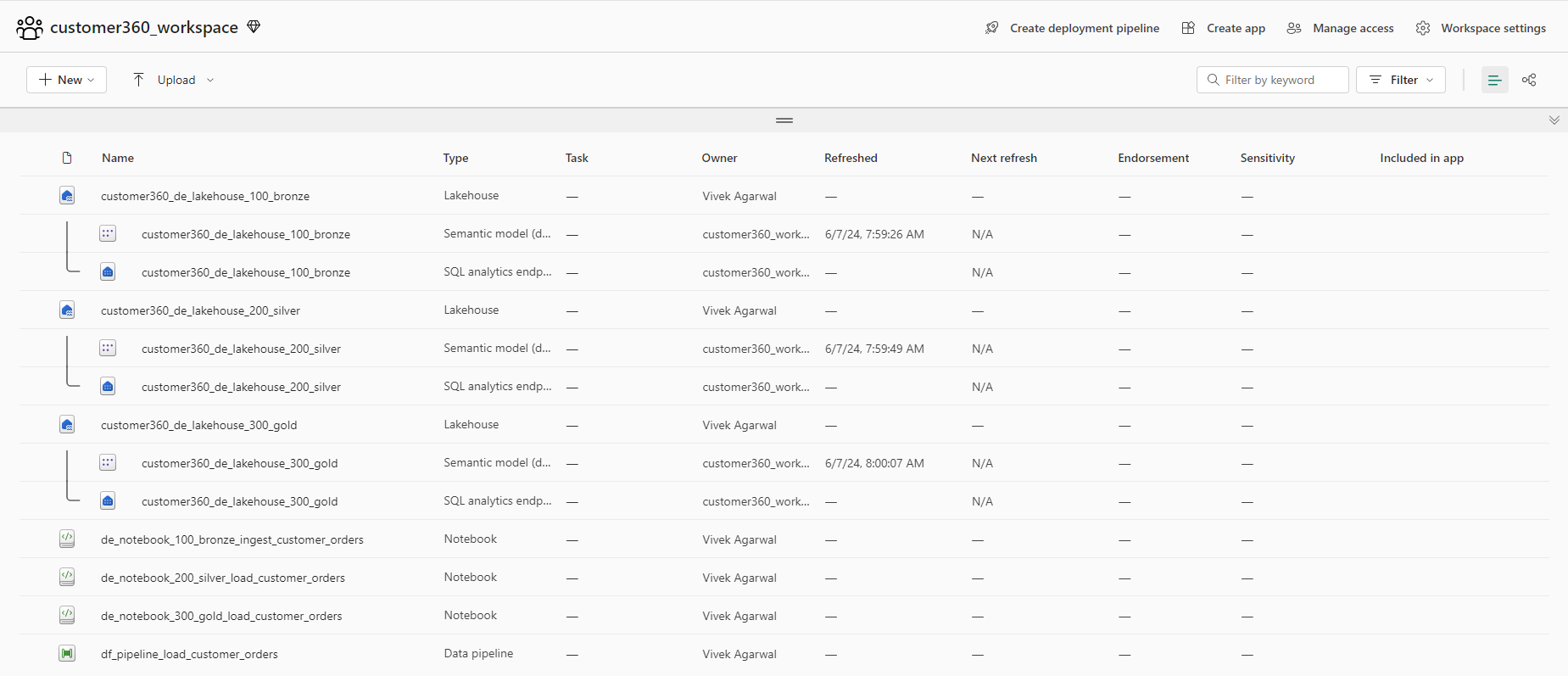
Initially, we will look at a listing of components within a single workspace where we have included the Project Name in the Lakehouse names but not in Data Pipelines, Dataflows Gen2, and Notebooks.
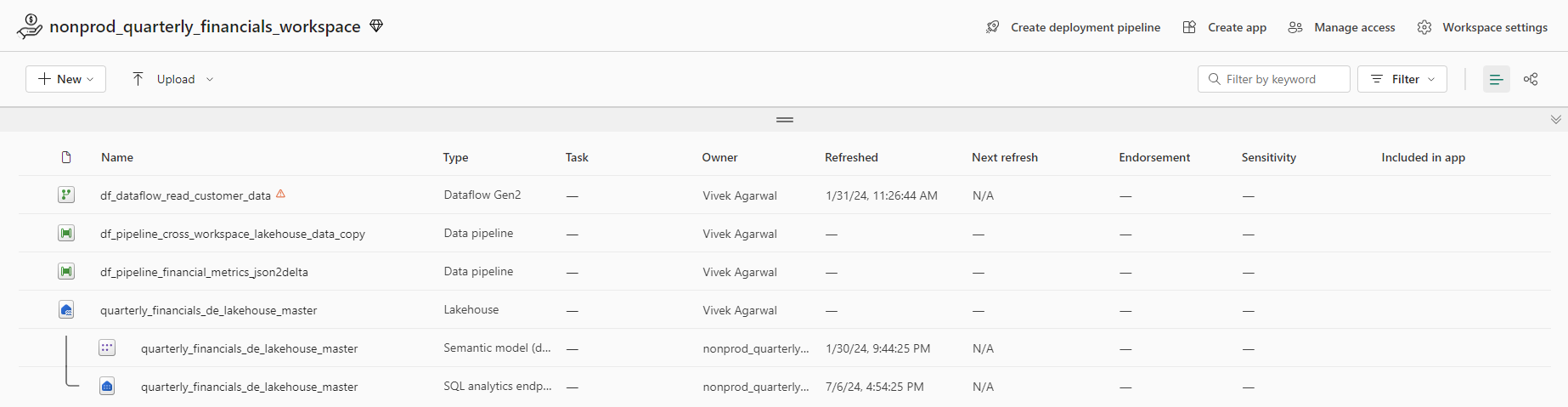
Next, we look at how these components appear in OneLake data hub, which provides a filterable list of all the data items you can access across all the workspaces. By including the Project Name in the lakehouses (and warehouses), we make it easy to understand where they live by just scanning the lakehouse (and warehouse) names.
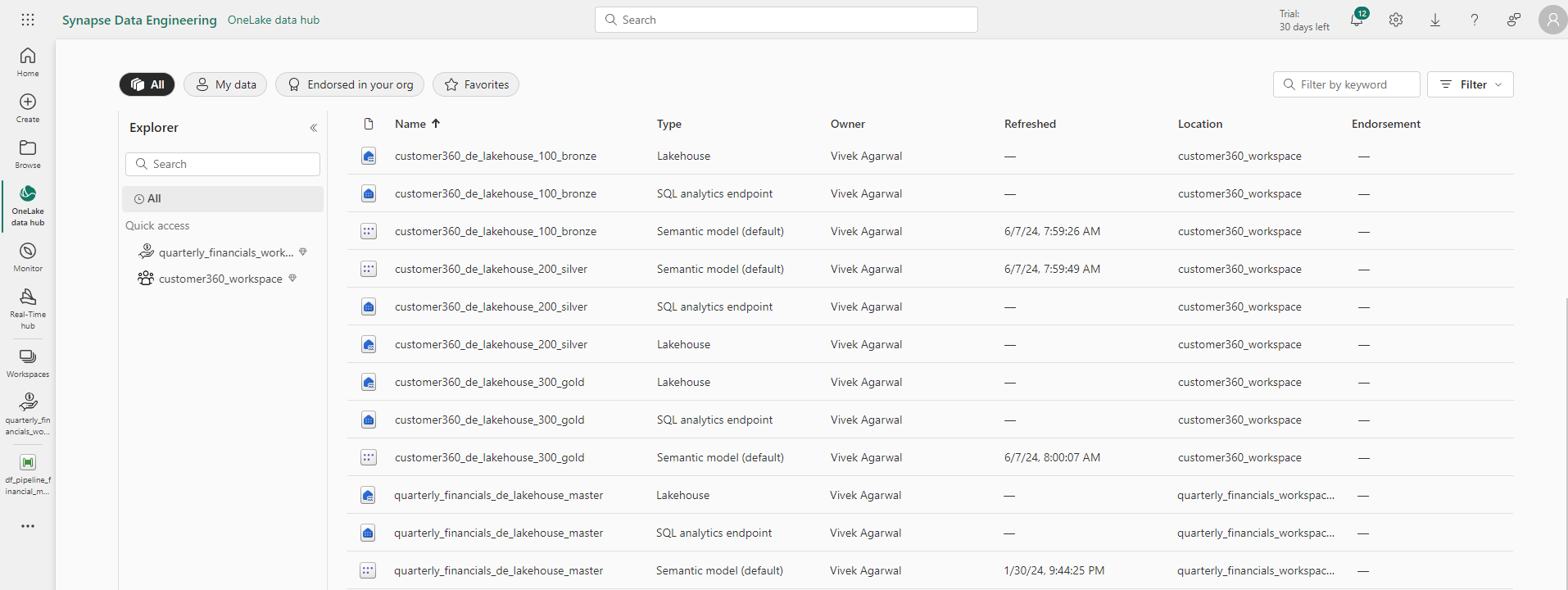
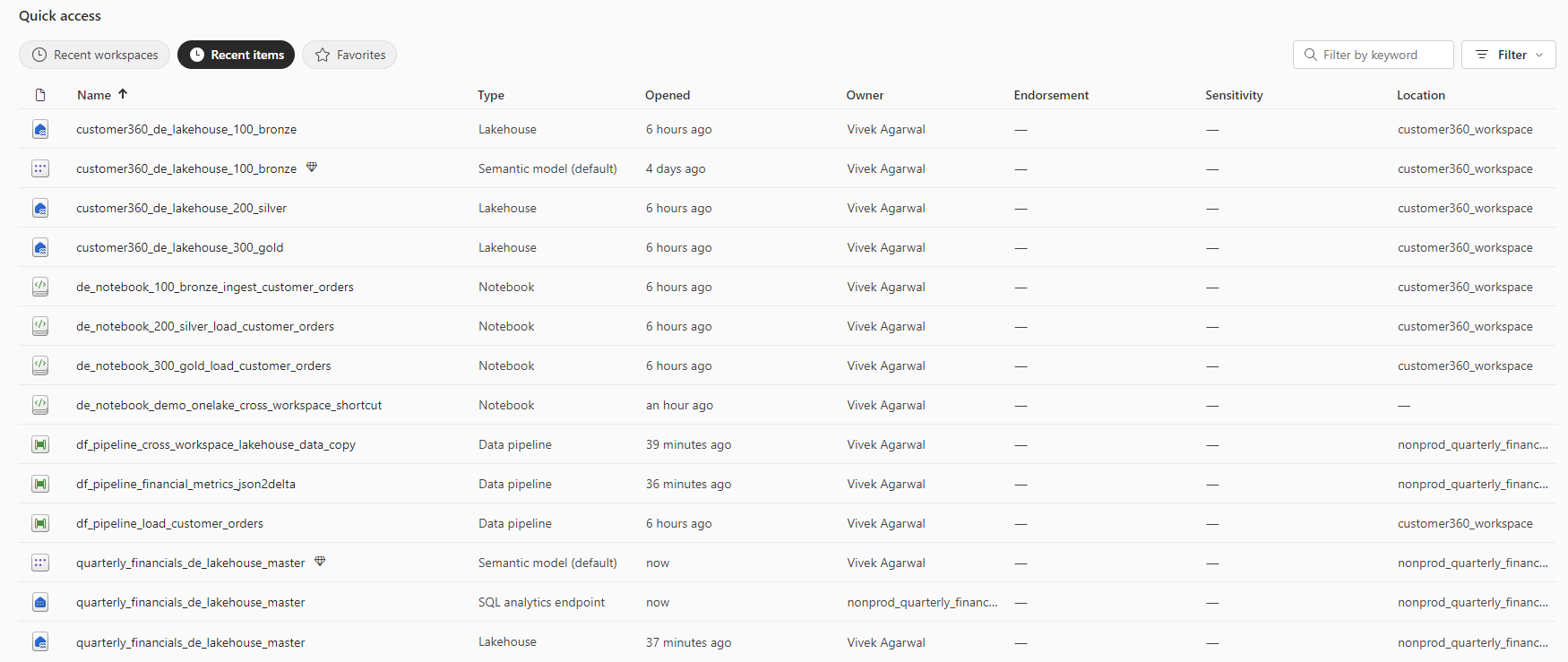
Lastly, let’s take a look at the list of recently viewed Fabric components in the Synapse Data Engineering Home view. Here, you can see how our naming conventions result in similar artifacts being grouped together by component type. Note that there is a balance to be struck in having a perfect grouping of artifacts versus overly long names, and this balance is specific to your preferences.
Conclusion: Naming Your Microsoft Fabric Resources
Calling all Data Architects and Engineers!
You and your organization are excited about Microsoft Fabric, and for good reason! Its end-to-end analytics and data capabilities delivered in a unified solution can unlock major benefits for you. But before diving in, consider the importance of effectively naming your Fabric resources.
We’ve developed a 6-parameter Microsoft Fabric naming framework to bring consistency and organization to your projects. This framework is flexible – you can choose to use all 6 parameters, the required parameters, or a combination that suits your team’s maturity and needs.
Don’t wait! Implementing this framework from the start will save you time and headaches down the road. A well-organized Microsoft Fabric environment keeps your data architects, data engineers, data scientists, and data analysts focused and efficient.
Remember: Clear naming conventions are key to maintaining and optimizing your Microsoft Fabric environment. Mastering this naming framework will set you up for success and maximize the value of Microsoft Fabric for your organization.
For any questions or more info, please contact us.