
It’s important to collect and leverage metadata to control the data pipelines (data ingestion, integration, ETL/ELT) in terms of audibility, data reconcilability, exception handling, and restartability. This article explores what we need to know for an optimal ETL process.
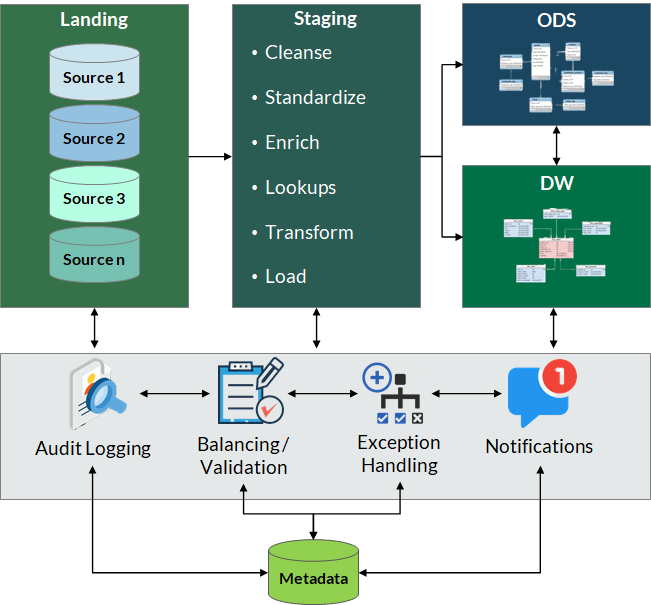
Typical ETL/ELT involves gathering data from sources, data sanity checks, data transformation (structural changes, data standardization, enrichment, etc.) with the possibility of some source data getting dropped/rejected depending on the business rules, and finally, loading the data to the target. Then what is Audit-Balance-Control? Let’s define the terms first.
Audit: Audit refers to maintaining a log of all the operations related to the ETL flow (the start/end date and time, number of rows processed, inserted, updated, and rejected/deleted in each step. One can take this to a deeper level and record the column-level audit report such as how many values are updated per column, etc.
Balance: We need to be able to explain the difference between the source(s) and target(s) in each step of the process, whether it’s a Data Integration, Data Migration, or any other process that copies/moves the data from a source to a target. It’s about ensuring data quality and integrity. This process primarily helps with data reconciliation.
Control: Control activity refers to the design aspect of restartability, exception handling, scheduling, and automation in general.
Data Collection
Audit, Balance, and Control can be effectively managed by collecting and utilizing data assets, processes, and operational metadata. Tools can be used to collect metadata from different sources (databases, reporting tools, ETL tools, etc.).
Audit
This data is very important for Balance and Control. We can collect all the operational data including the start- and end-time of the ETL/ELT jobs, steps, number of records processed, rejected, type of errors, warning, etc. Apart from providing the general audit capabilities to the processes, this data also helps us investigate production issues, analyze the process performance trends, and provide further automation. The possibilities are endless.
Balance
We need to be able to explain the differences between source and target data objects when the data is copied, moved, and/or transformed from a source to a target. This can be done in different ways. It can be as simple as row counts comparison or a complex process of running a set of business rules to “quality check” the target data. Automated processes need to be developed and a scheduled run of these processes should produce exception reports where applicable.
When data is copied or moved from a source to a target (without any structural changes), we can compare the row counts, the sum of numeric columns, row counts by key columns, etc. Date columns can be checked for formats. This is relatively simple.
When data gets transformed from source to target, the process of comparing the source and target is relatively complex, but it is not practical, nor advisable to duplicate the entire transformation process to quality check data between source and target. Based on the requirements and mapping specifications — with the help of data stewards and application SMEs — one needs to develop simple processes to reconcile the data between source and target to be able to explain the differences.
Control
Restartability: One of the “control” aspects is about designing the processes to make them more flexible and “smart” in restarting from the last point of failure instead of restarting from the beginning.
Exception Handling: The data integration and ETL/ELT processes should be able to catch, notify, and automatically correct (as much as possible) all types of exceptions. The quality of data related to business teams, IT teams, related contact details, exception codes, and descriptions play a very important role in handling exceptions and resolving them quickly.
Again, the “control” aspect of the data integration and ETL/ELT heavily depends on the quality and granularity of the process audit/log data collected.
Guidelines
- Metadata collection is key: Metadata collection, completeness, and quality are an integral part of a good ETL process. Commercial metadata management tools, along with the data collected by the ETL process itself, help achieve this.
- Consider trade-offs: Though there is no limit to the amount of metadata we can collect, the requirements dictate the type of metadata we need to collect, the level of detail, when we need to collect, who needs access to this data, how it’s collected, and where it’s stored. One needs to keep in mind that collecting and updating different types of metadata has overhead associated with it.
- Leverage the operational metadata collected by the ETL tool as much as possible.
- The data that needs to be collected manually (or the data collection that depends on human intervention), needs special attention. For instance, related data between the Business Teams and IT Teams can be collected with the help of a portal, or Operations can have the teams update the data on a shared file.
- Security: Access to metadata must be restricted, as it is the most valuable enterprise asset. All-access to metadata must be logged and audited.
- Data Dictionary: Metadata should include a data dictionary, which is essential for anyone to understand and make sense of the data.
- Reporting: The very purpose of collecting the metadata is to be able to increase automation and provide data for root cause analysis. It’s very important to have reporting capabilities to view and analyze the data regardless of the tools used to collect the metadata.
With an understanding of ETL Audit-Balance-Control best practices and guidelines, your organization can leverage better control over your data pipeline and gain a competitive edge within your industry. If your business is struggling with its ETL processes, reach out to XTIVIA today!